11.04.2024 00:15
 |
Автор: Администратор
|

С тех пор, как появились “большие данные”, качество данных оставалось под большим вопросом. Работа с данными, чтобы сделать их пригодными для анализа, была задачей, на решение которой специалисты по обработке данных тратили большую часть своего времени 15 лет назад, и последние данные свидетельствуют о том, что сейчас, когда мы вступаем в эпоху искусственного интеллекта, эта проблема становится еще более актуальной. Одно из последних свидетельств того, что качество данных - это постоянная проблема, поступило к нам от dbt Labs, компании, создавшей инструмент dbt с открытым исходным кодом, который широко используется командами разработчиков данных.
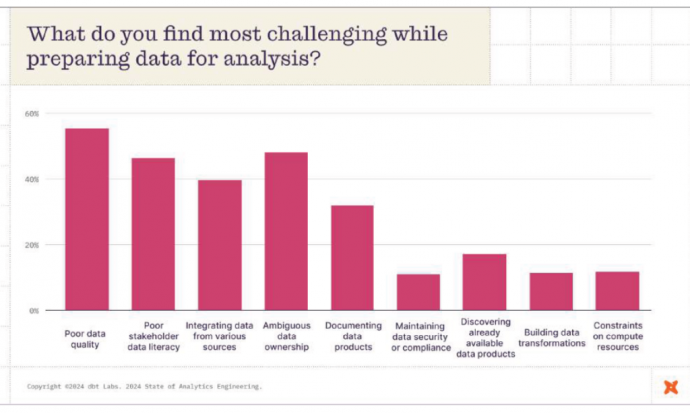
Согласно опубликованному вчера отчету компании State of Analytics Engineering за 2024 год, плохое качество данных было главной проблемой для 456 инженеров-аналитиков, проектировщиков обработки данных, аналитиков данных и других специалистов по обработке данных, которые приняли участие в опросе. В отчете показано, что 57% респондентов, участвовавших в опросе, оценили качество данных как один из трех наиболее сложных аспектов процесса подготовки данных. Это значительно больше, чем в отчете о состоянии аналитической техники за 2022 год, в котором 41% указали, что низкое качество данных было одной из трех основных проблем.
Качество данных - не единственная проблема. Среди других проблем, которые беспокоят специалистов по обработке данных, - неупорядоченность владения данными, низкая информационная грамотность, интеграция нескольких источников данных и документирование информационных продуктов. Все это перечислили 30% инженеров, аналитиков, ученых и менеджеров, участвовавших в опросе в прошлом месяце. Меньшие проблемы связаны с безопасностью и соответствием требованиям, поиском информационных продуктов, преобразований данных и ограничениями на вычислительные ресурсы.
На вопрос о том, будут ли их организации увеличивать или уменьшать инвестиции в повышение качества данных и их наблюдаемость, около 60% респондентов, участвовавших в опросе dbt, ответили, что сохранят эти инвестиции на прежнем уровне, в то время как около 25% заявили, что увеличат их. Только около 5% заявили, что в следующем году они сократят инвестиции в управление качеством данных и их наблюдаемость.
Компания Dbt - не единственный поставщик, который обнаружил, что качество данных ухудшается. Год назад компания Monte Carlo, занимающаяся обеспечением наблюдаемости данных, опубликовала отчет, в котором были сделаны аналогичные выводы. Отчет поставщика о состоянии качества данных показал, что количество инцидентов, связанных с качеством данных, растет, и среднее число инцидентов в каждой организации увеличилось с 59 до 67 в 2023 году.
Другой поставщик средств обеспечения доступности данных, Bigeye, также обнаружил, что качество данных вызывает наибольшую обеспокоенность у его пользователей. Было установлено, что пятая часть компаний за предыдущие шесть месяцев столкнулась с двумя или более серьезными инцидентами с данными, которые непосредственно повлияли на прибыль бизнеса. В нем говорилось, что в среднем компания сталкивается с пятью-десятью инцидентами, связанными с качеством данных, в квартал.
Тенденция к снижению качества данных ведет к тому, что они не способствуют укреплению доверия, особенно в связи с тем, что данные становятся все более важными для принятия решений. По мере того, как компании начинают полагаться на прогнозную аналитику и искусственный интеллект, потенциальное влияние некачественных данных возрастает еще больше. По оценкам Gartner, в 2021 году низкое качество данных обходилось организациям в среднем в 12,9 миллионов долларов в год, что является ошеломляющей суммой. Однако эксперты из Стэмфорда, штат Коннектикут, ожидали, что в ближайшие годы качество данных будет только повышаться, а не снижаться.
Некачественные данные особенно вредны для генеративного ИИ. В феврале исследование Informatica, в ходе которого изучались основные проблемы при внедрении GenAI, показало, что, как вы уже догадались, качество данных стоит на первом месте в списке. Опрос показал, что 42% руководителей в области обработки данных, которые в настоящее время внедряют GenAI или планируют это сделать, назвали качество данных главным фактором успеха GenAI.
Сможем ли мы когда-нибудь решить проблему качества данных раз и навсегда? По словам Джигнеша Пателя, профессора компьютерных наук Университета Карнеги-Меллон и соучредителя DataChat, это маловероятно. “Данные никогда не будут полностью очищены”, - сказал он. “Вам всегда понадобится некоторая часть ETL”. По словам Пателя, причина, по которой качество данных никогда не будет “решенной проблемой”, отчасти заключается в том, что данные всегда будут собираться из различных источников различными способами, а отчасти в том, что качество данных зависит от наблюдателя.
“Вы постоянно собираете все больше и больше данных”, - сказал недавно Патель в интервью Datanami. “Если вы сможете найти способ получить больше данных, и никто не скажет "нет", это всегда будет грязно. Это всегда будет грязно”. Если пользователю удалось получить “идеальный” набор данных для одного конкретного проекта по анализу данных, нет никакой гарантии, что он будет “идеальным” для следующего проекта. “В зависимости от типа анализа, который я провожу, он может быть абсолютно точным, а может быть и совершенно грязным”, - сказал он.
Данные из отчетов собрал Алекс Вуди из Datanami